由于项目需要用到大量的农业科普信息数据,所以通过爬虫来获取这些信息并写入数据库
整体思路
整体的思路就是先查看网站的源代码,看看是否可爬,以及数据是否要通过接口来获取,然后根据每个网页源码中的具体字段来获取标题,来源,作者等等信息,最后再写入数据库
这里 我爬取的网站以中国农业信息网为例
基础配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import warnings
warnings.filterwarnings("ignore",category=DeprecationWarning)
import requests
from bs4 import BeautifulSoup
import pymysql
DB_HOST = "localhost"
DB_PORT = 3306
DB_USER = "root"
DB_PASSWORD = "123456"
DB_NAME = "crawling_agriculture"
base_url_front = 'http://www.agri.cn/was5/web/search?channelid=211475&keyword=%E7%A7%91%E6%99%AE&perpage=10&page='
base_url_back = '&orderby=-docreltime'
|
获取总网页中的各个分页面链接
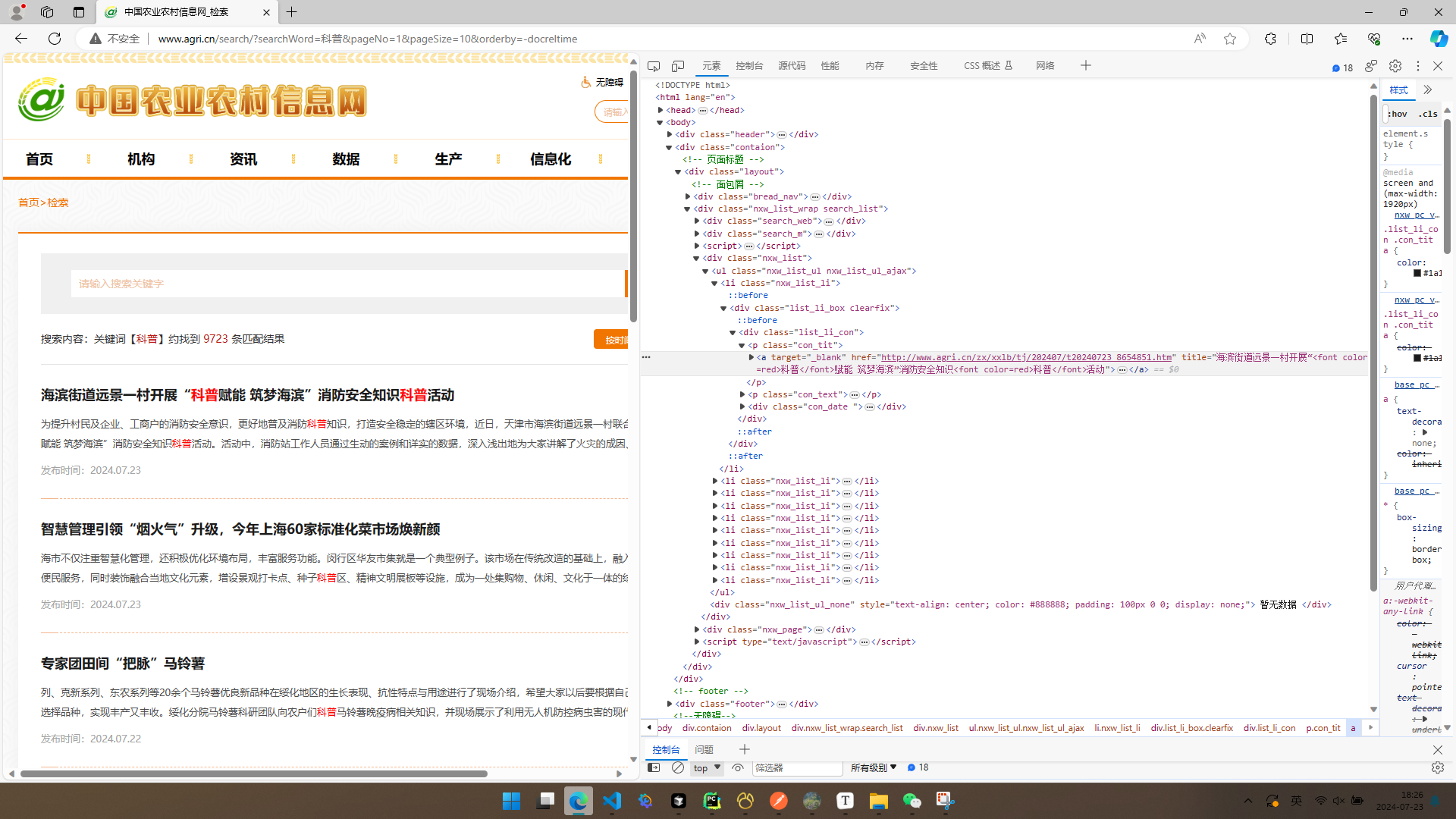
首先,我们观察这个网页及其网页的源代码我们可以发现,网页源码中有一部分内容被隐藏了,因此,需要通过接口来实现
通过接口获取隐藏内容参考: 获取隐藏了部分内容的网页源代码,审查元素可以,查看源代码不行。学习python爬虫_爬虫获取的网页源码有隐藏-CSDN博客
1
2
3
4
5
6
7
8
9
10
11
| {
"code": 0,
"recordCount": 9721,
"pageSize": 10,
"currentPage": 1,
"items": [
{
"docabstract": "列、克新系列、东农系列等20余个马铃薯优良新品种在绥化地区的生长表现、抗性特点与用途进行了现场介绍,希望大家以后要根据自己的土地现状、市场供需实际选择品种,实现丰产又丰收。绥化分院马铃薯科研团队向农户们科普马铃薯晚疫病相关知识,并现场展示了利用无人机防控病虫害的现代科技。乡亲们按各自需求一一咨询。有种植户拿出田里生病的马铃薯秧请专家们“把脉”,并认真记下专家们给的“药方”。 专家团来到北林区兴福乡民权",
"docid": "8654549",
"docreltime":"2024.07.2212: 02: 00","doctitle":"专家团田间“把脉”马铃薯","docpuburl":"http: //www.agri.cn/zx/xxlb/hlj/202407/t20240722_8654549.htm"}......
|
观察接口内容,我们发现我们需要的各个页面的链接在docpuburl字段里面 所以我们需要获取到这个字段内容,并存在一个列表中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| for page in range(1, 3):
page_links = []
url = f'{base_url_front}{page}{base_url_back}'
base_response = requests.get(url)
if base_response.status_code == 200:
try:
parsed_data = base_response.json()
except ValueError:
print("响应内容不是有效的 JSON 格式")
print(base_response.text)
else:
print(f"请求失败,状态码: {base_response.status_code},网址:{url}")
for item in parsed_data['items']:
if item['doctitle'] and item['docpuburl']:
page_links.append(item['docpuburl'])
|
在上面代码中,我们先定义一个列表来存储访问各个网页的链接,然后组成 用来获取不同页码中隐藏内容的接口链接,然后使用try-except捕捉报错信息(如果因为这个链接报错的话),最后把接口获取到的每一个网页的跳转链接写入到列表中,接下来就可以对每个页面进行单独分析 来编写爬取各个页面的代码了
各个页面具体信息获取
标题的爬取
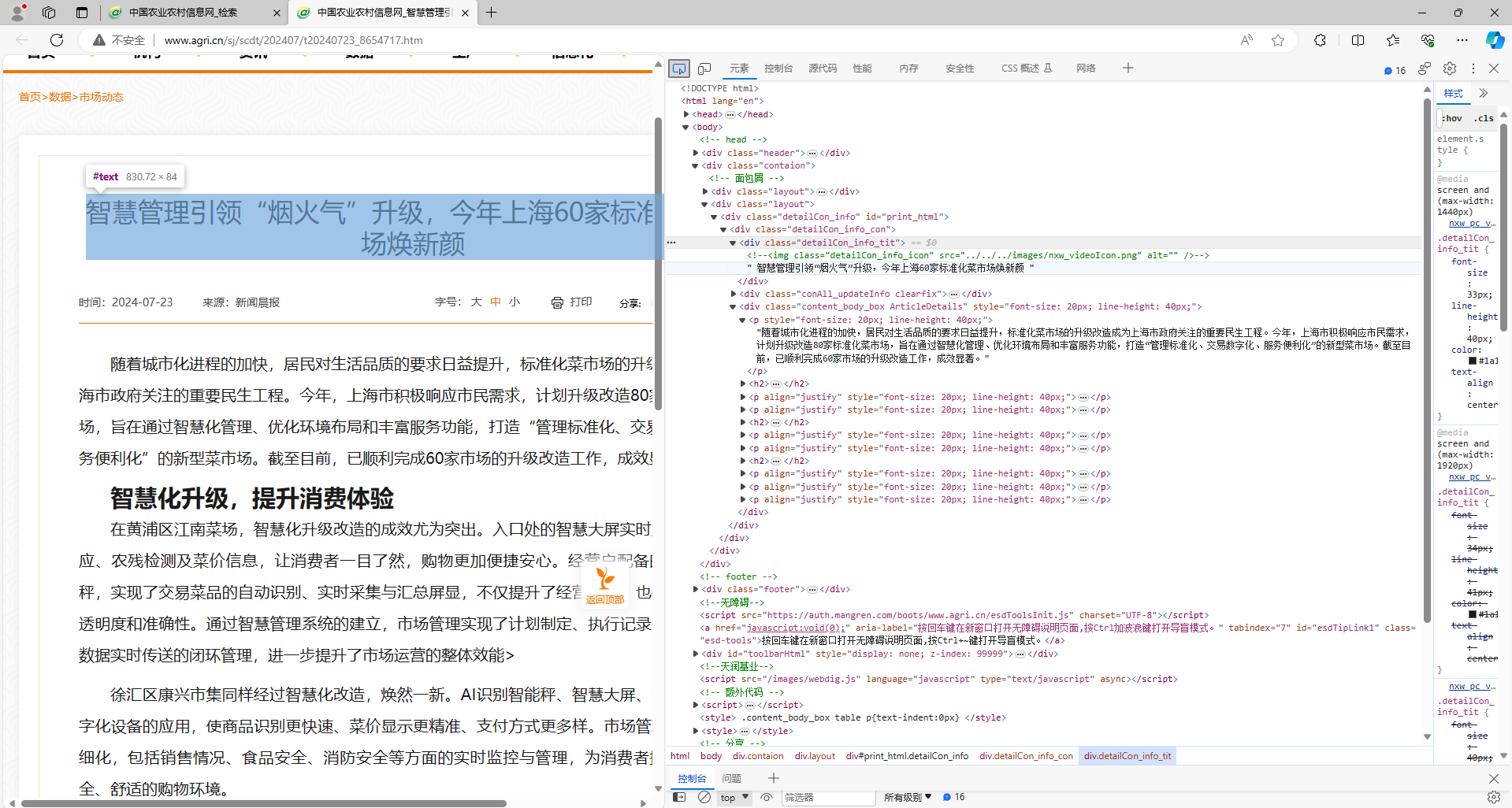
首先来看页面中源码,我们可以发现标题在<div class="detailCon_info_tit"> </div>标签中 当然,光看这一个页面是不行的,通过查看多个网页源码,发现标题都在<div class="detailCon_info_tit"> </div>标题中,所以我们就以这个为基础来写(有不一样的后期再改)
1
| title = page_soup.find('div', class_="detailCon_info_tit").get_text(strip=True)
|
这里我是使用的beautifusoup来获取的,如果你习惯使用正则表达式也一样,代码中的get_text(strip=True) 方法是获取标签中的文本,以及删除两端多余的空格
作者,来源,发布时间的爬取
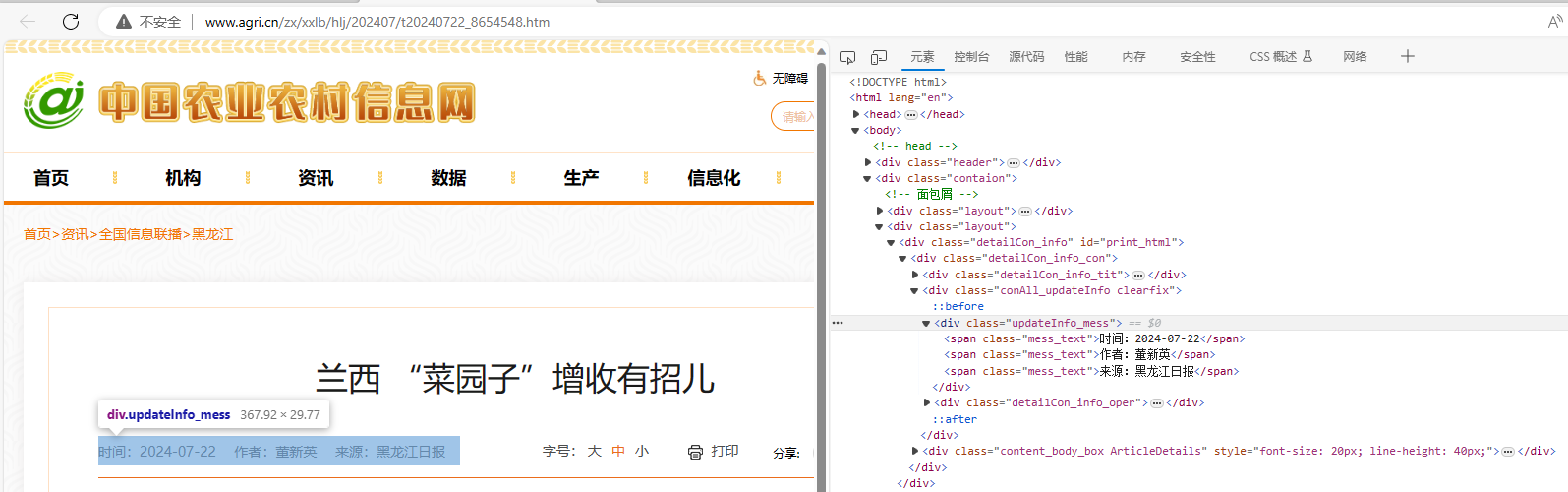
同样的 观察这个网页源代码我们可以发现 作者,来源, 和发布时间都在<span class="mess_text"></span>标签里面 然鹅 通过观察多个网页源码发现 有的网页他 没有作者信息

所以 这个时候我们就需要来判断一下 作者信息是否为空 再来获取
1
2
3
4
5
6
|
author_span = page_soup.find_all('span', class_='mess_text')[1].text
if author_span != '':
author = author_span.split(':')[1]
else:
author = author_span
|
在上面代码中 我们先使用find_all方法查找出<span class="mess_text"></span>标签中所有的信息即 :发布时间,作者,来源,因为find_all方法返回的是一个列表,所以我们使用索引下标方式来获取包含作者信息的span标签 ,然后使用text属性,获取<span>标签中的文字内容,不包括任何HTML标签。如果作者信息不为空时,我们将span标签中的作者信息利用split方法分割,因为标签中的作者信息形如 作者:*** 而我们只需要具体名字。
对于发布时间和来源,同理
1
2
| publish_date = page_soup.find_all('span', class_='mess_text')[0].text.split(':')[1]
source = page_soup.find_all('span', class_='mess_text')[2].text.split(':')[1]
|
内容和图片链接的爬取

通过观察 我们能发现 这个页面的内容,保存在了<div class="content_body_box ArticleDetails"></div>标签里面,因此 我们可以通过获取这个标签中的内容来获取这个页面内容
1
| content = page_soup.find('div', class_='content_body_box ArticleDetails').get_text().strip('\n')
|
但是!通过多次观察以及报错经历 发现事情并不会这么简单 这个网站中的页面内容有好几种存储方式 这里我选择其中三种占比最多的 其他就不管了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| if page_soup.find('div',class_="content_body_box ArticleDetails"):
content = page_soup.find('div', class_='content_body_box ArticleDetails').get_text().strip('\n')
relative_url = '/'.join(page_url.split('/')[:-1])
images = []
for img in page_soup.find('div', class_='content_body_box ArticleDetails').find_all('img'):
src = img['src']
if not src.startswith('http'):
src = f'{relative_url}/{src.lstrip("./")}'
images.append(src)
elif page_soup.find('div', class_='ArticleDetails'):
content = page_soup.find('div', class_='ArticleDetails').get_text().strip('\n')
images = ''
elif page_soup.find('div',class_="Custom_UnionStyle"):
content = page_soup.find('div', class_="Custom_UnionStyle").get_text().strip('\n')
images = ''
|
在上面代码中,我们先判断网页保存内容的标签是否为我们选取的,如果是,则用get_text()方法获取文本并利用strip()方法分割
其他两种也类似
图片的爬取
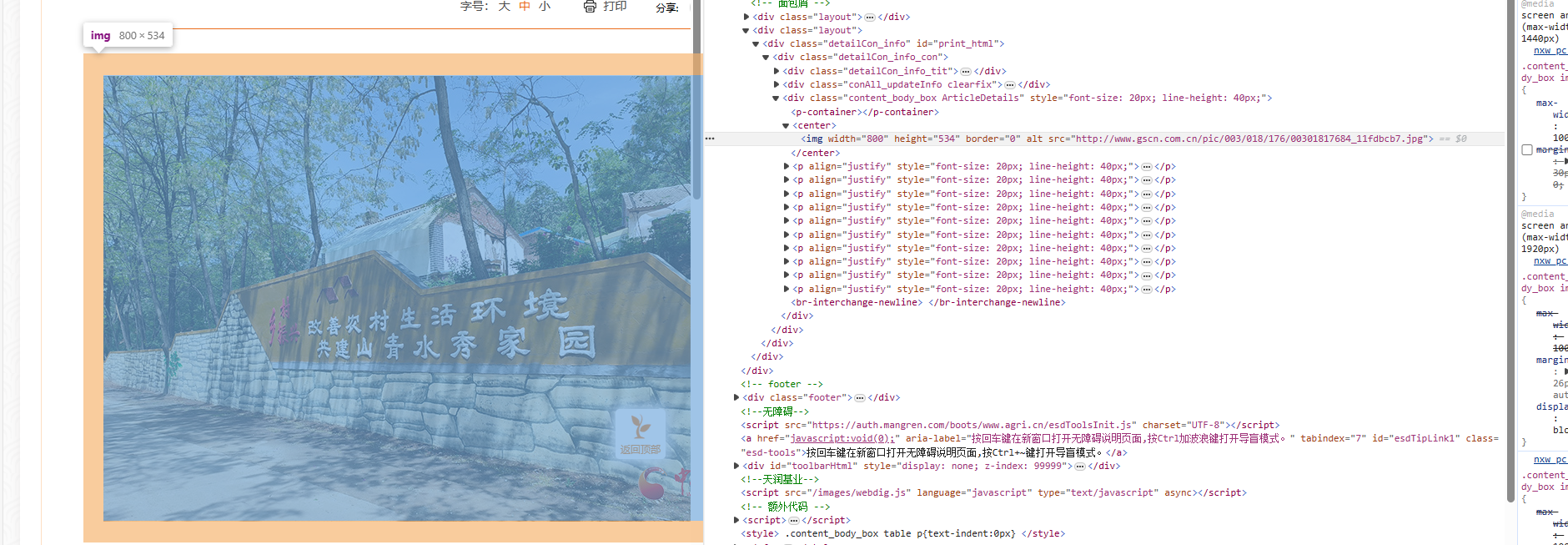
通过观察我们可以发现 图片的链接都保存在img标签里面,所以,我们只需要筛选出img标签,就可获取img标签中对应的的src链接,但是还有一个问题,有的网页的图片链接是用的相对路径来保存的,这时候需要将网页网址和他的相对路径结合,才能获取这个图片真正的链接
1
2
3
4
5
6
7
8
9
10
11
12
| relative_url = '/'.join(page_url.split('/')[:-1])
images = []
for img in page_soup.find('div', class_='content_body_box ArticleDetails').find_all('img'):
src = img['src']
if not src.startswith('http'):
src = f'{relative_url}/{src.lstrip("./")}'
images.append(src)
elif page_soup.find('div', class_='ArticleDetails'):
images = ''
elif page_soup.find('div',class_="Custom_UnionStyle"):
images = ''
|
在上面代码中,我们先获取到网页链接中图片的相对路径需要的部分,比如网址链接为:“http://www.agri.cn/zx/xxlb/gx/202406/t20240629_8647462.hthttp://www.agri.cn/zx/xxlb/gx/202406/t20240629_8647462.htmm”而我们需要的部分是 ”http://www.agri.cn/zx/xxlb/gx/202406“ 后面再加上图片的相对路径 如:http://www.agri.cn/zx/xxlb/gx/202406/W020240629376394428648.jpg
经过大量的测试发现,图片只有在<div class="content_body_box ArticleDetails"></div>标签里面才会出现
写入数据库
现在我们已经获取到了标题,作者,发布时间,来源,内容,图片,网址 接下来写入数据库
1
2
3
4
5
| cursor.execute('''INSERT INTO news_copy2 (title, content, author, publish_date, source, url, images)
VALUES (%s, %s, %s, %s, %s, %s, %s)''', (title, content, author, publish_date, source, page_i, ','.join(images)))
conn.commit()
conn.close()
|
写入数据库很简单 就不多说了
成品
在上面的基础之上再加上一些异常捕获机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| import warnings
warnings.filterwarnings("ignore",category=DeprecationWarning)
import requests
from bs4 import BeautifulSoup
import pymysql
import re
DB_HOST = "localhost"
DB_PORT = 3306
DB_USER = "root"
DB_PASSWORD = "123456"
DB_NAME = "crawling_agriculture"
base_url_front = 'http://www.agri.cn/was5/web/search?channelid=211475&keyword=%E7%A7%91%E6%99%AE&perpage=10&page='
base_url_back = '&orderby=-docreltime'
for page in range(1, 974):
page_links = []
url = f'{base_url_front}{page}{base_url_back}'
base_response = requests.get(url)
if base_response.status_code == 200:
try:
parsed_data = base_response.json()
except ValueError:
print("响应内容不是有效的 JSON 格式")
print(base_response.text)
else:
print(f"请求失败,状态码: {base_response.status_code},网址:{url}")
for item in parsed_data['items']:
if item['doctitle'] and item['docpuburl']:
page_links.append(item['docpuburl'])
for page_i in page_links:
page_url = page_i
page_response = requests.get(page_url)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
try:
title = page_soup.find('div', class_="detailCon_info_tit").get_text(strip=True)
author_span = page_soup.find_all('span', class_='mess_text')[1].text
if author_span != '':
author = author_span.split(':')[1]
else:
author = author_span
publish_date = page_soup.find_all('span', class_='mess_text')[0].text.split(':')[1]
source = page_soup.find_all('span', class_='mess_text')[2].text.split(':')[1]
if page_soup.find('div',class_="content_body_box ArticleDetails"):
content = page_soup.find('div', class_='content_body_box ArticleDetails').get_text().strip('\n')
relative_url = '/'.join(page_url.split('/')[:-1])
images = []
for img in page_soup.find('div', class_='content_body_box ArticleDetails').find_all('img'):
src = img['src']
if not src.startswith('http'):
src = f'{relative_url}/{src.lstrip("./")}'
images.append(src)
elif page_soup.find('div', class_='ArticleDetails'):
content = page_soup.find('div', class_='ArticleDetails').get_text().strip('\n')
images = ''
elif page_soup.find('div',class_="Custom_UnionStyle"):
content = page_soup.find('div', class_="Custom_UnionStyle").get_text().strip('\n')
images = ''
else:
continue
except Exception as e:
print(f"错误发生在页面: {page_url}, 错误信息: {e}")
continue
conn = pymysql.connect(host=DB_HOST, port=DB_PORT, user=DB_USER, password=DB_PASSWORD, db=DB_NAME, charset='utf8')
cursor = conn.cursor()
try:
cursor.execute('''INSERT INTO news_copy2 (title, content, author, publish_date, source, url, images)
VALUES (%s, %s, %s, %s, %s, %s, %s)''', (title, content, author, publish_date, source, page_i, ','.join(images)))
conn.commit()
except pymysql.err.DataError as e:
print(f"数据插入错误,跳过该条记录: {e}")
continue
finally:
conn.close()
|